NVIDIA Maxwell caractéristiques architecturales Dévoilées – Projet Denver à paraître avec Maxwell Refresh?
De nouvelles informations concernant les puces NVIDIA Maxwell et leur architecture ont été divulguées par un utilisateur sur pastebin. Diverses rumeurs qui concerne les puces, rappelons qu’il faut relativiser le sérieux de ces nouvelles plus ou moins obscures. Cependant une partie de l’information est très plausible et nous y avons jeté un coup d’oeil quand même afin d’en décrypter l’essentiel.
[Allégations] NVIDIA – Maxwell: caractéristiques architecturales dévoilées
NVIDIA va présenter leur dernière architecture Maxwell l’année prochaine, ce qui va introduire une nouvelle conception de l’architecture de base, avec de nouveaux niveaux de performances graphiques dans les jeux et les applications lourdes. NVIDIA prévoit d’introduire quatre puces l’année prochaine qui comprennent les GM100, GM104, GM106 et GM108. Par rapport à Kepler, ces nouvelles puces NVIDIA Maxwell comporteraient une structure unitaire SMX (multiprocesseur de flux) légèrement amélioré et quelques optimisations de sorte que l’unité logique de l’algorithme double précision peut désormais être utilisé pour la simple précision afin de soutenir toutes les nouvelles instructions de SP (Single Precision).
Au lieu de 192 ALU (Unité Arithmétique Logique), une unité SMX unique serait désormais équipés de 256 ALU (Integer Arithmetic Logic Unit) qui permettrait de réduire le taux DP (Double Precision) de Maxwell à 1:4. Bien que techniquement cela ressemble à un downgrade sur Kepler, le rendement réel augmenterait le nombre SP sur Kepler. Cela va économiser de l’énergie lorsque vous utilisez les performances SP depuis les processus DP non utilisées de l’ALU seraient éteints. NVIDIA a également fait quelques changements avec la hiérarchie de cache de premier rang pour Maxwell avec l’ajout de deux registres par unité SMX et les échanges avec une énorme quantité de registres peuvent maintenant fonctionner en parallèle les uns des autres. Le cache L1 est soi-disant passé à 128kb par rapport au 64kb sur Kepler et peut être utilisé comme mémoire partagée. Il peut être partagé entre la mémoire cache et la mémoire partagée selon les étapes suivantes – 32/96, 64/64 ou 96/32. Tout comme Kepler avant lui, NVIDIA Maxwell comporterait 16 TMU (unités de texture mapping) par SMX.
En plus de la mémoire cache L1, chaque GPC (Graphics Processing Cluster) serait également en vedette avec son propre cache L2 de 768KB servant de cache d’instruction de la SMX. En ce qui concerne les spécifications de chaque puce NVIDIA Maxwell, vous pouvez les trouver ci-dessous:
NVIDIA Maxwell GM100:
La puce NVIDIA Maxwell GM100 serait composé de 8 GPC (Graphics Processing Cluster) composé de 24 modules SMX (3 SMX par GPC), 384 TMU (unités de texture mapping), 6144 Cuda Cores, 8 Mo de cache L3 (8 cache L2 par GPC), 64 ROPs, une interface 512 bits suivie d’une VRAM jusqu’à 8 Go GDDR5 opérant à environ 6 GHz. Le GM100 est censé remplacer la puce GK110 haute performance faisant partie des séries GeForce et Tesla. Il apparaîtra probablement dans les Tesla en premier lieu avant de débarquer dans les séries GeForce pour les consommateurs.
Les fréquences d’horloge seraient maintenus à des niveaux différents pour chaque produit tier énumérés ci-dessous:
• GeForce GM100: 930 MHz de base / 1 GHz Boost • Tesla GM100: 850 MHz (2,61 téraflops DP)
NVIDIA Maxwell GM104:
La NVIDIA GM104 remplacerait l’actuelle puce GK104 que nous avons appris à connaître et à aimer depuis l’arrivée de la GeForce GTX 680. Cette puce serait composée de 5 GPC (Graphics Processing Cluster) avec 15 unités SMX comportant 3840 Cuda Cores, 240 TMU, 40 ROP avec une interface 320 bits sortant avec 3 Go de VRAM (éventuellement 2,5 Go en fait avec Fermi) cadencé à environ 7 GHz pour la mémoire et 1 GHz pour le noyau.
NVIDIA Maxwell GM106:
Le GM106 serait remplaçant de la plupart des Kepler (dans la gamme de prix de 249USD) comme la GeForce GTX 660 et GeForce GTX 650 Ti / Boost qui étaient basés autour de l’architecture de base du GK106.
Spécifications, ces puces devraient voir une augmentation massive de 960 cores par rapport à la génération Kepler ce qui élèverait à 2304 ALU sur les GM106. Ceux-ci devraient disposés de 3 GPC. Comme le GM104, le GM106 comporterait 4 Mo de cache L3, 144 TMU, 24 ROP et une interface 192 bits avec 3 Go de VRAM fonctionnant à 7 GHz pour les vitesses d’horloge .
NVIDIA Maxwell GM108:
La dernière puce serait le niveau d’entrée de gamme, le GM108 qui est une étape derrière le GM107 qui n’est pas encore détaillées, mais cette puce est récemment apparu dans les derniers pilotes ES qui peut être vu ici .
L’échantillon de l’ES actuel énumère les caractéristiques suivantes: – 576 cœurs CUDA, 48 TMU, 8 ROPs, contrôleur de mémoire 64 bits et une taille de matrice similaire à GF117.
NVIDIA Project Denver à apparaître dans Maxwell Refresh?
En ce qui concerne le très attendu Project Denver qui est censé être lancé avec Maxwell est censée débuté avec les cartes graphiques Maxwell refresh. L’utilisateur indique que NVIDIA va attendre que le nouveau processus de FinFET soit utilisé pour préparer le Projet Denver avant de l’appliquer sur Maxwell. Il y a une certaine vérité en ce qui concerne cette information puisque NVIDIA a présenté leur feuille de route Tegra au GTC 2013, qui présentait son SOC Parker avec NVIDIA Maxwell et le CPU projet Denver à l’intérieur d’une matrice qui sera fabriquée à l’aide du nouveau processus de FinFET.
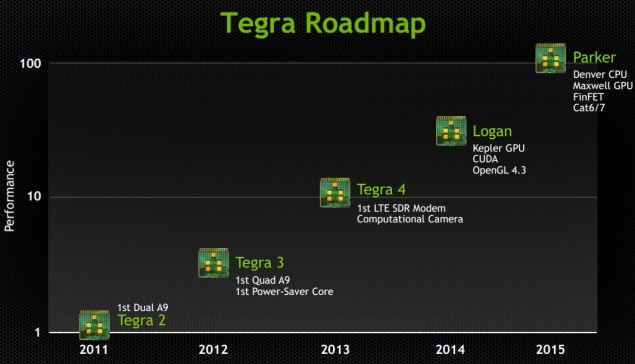
Le CPU Projet Denver utilise une architecture composée de Cores ARM 64 bits qui seraient fusionnés aux côtés du DIE GPU. Les spécifications resteraient les mêmes que pour les GM110, GM114, GM116 avec seulement la partie GM110 qui obtiendrait le plein potentiel des 8 coeur du CPU Denver. La partie GM110 serait en fait connu comme le GM110SOC, le SOC représente une conception du système sur la puce. La version grand public de la GM110 avec Denver serait doté de quatre cœurs ainsi que la puce GM114 tandis que la partie GM116 ne comporterait que deux noyaux. L’utilisateur a mentionné que GM118 n’a pas été mentionné avec Project Denver, il est donc probable qu’il ne sera pas avec la nouvelle architecture.
Projet Denver serait doté d’un lien cohérent pour le cache L3 afin de décharger le travail lourd du CPU. L’utilisateur affirme également que NVIDIA croit en leur Projet Denver et l’optimisation du pilote donneraient un coup de pouce supérieur à leurs cartes ayant une API propriétaire comme Mantle d’AMD avec leurs produits GCN. Beaucoup reste encore à être confirmé en ce qui concerne Maxwell, mais des rapports similaires avaient émergés quelques mois avant le lancement de Kepler et s’étaient avéré être précis.
La chose la plus importante que nous ne pouvons pas confirmer pour le moment est de savoir si ces puces seraient disponibles au 1er trimestre 2014 ou non, puisque TSMC devrait commencer la production de masse de leurs puces 20nm en Février 2014 et AMD qui a récemment lancé leur série (Volcanic Island) Iles volcaniques ne ferait que répondre à leurs nouvelles puces à compté du 1er trimestre 2014 avec de nouveaux produits jusqu’à la fin de 2014 ou au début de 2015. Cela signifierait que pour le début de 2014 il s’agirait surtout du lancement de nouvelles puces mobiles d’AMD (série Crystal) et NVIDIA (GeForce 800M Series) avec des solutions de bureau.
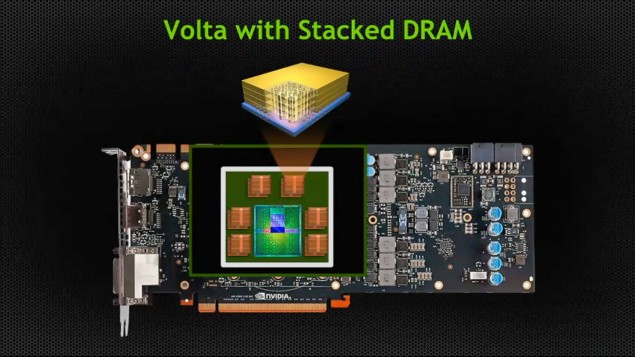
En 2016, NVIDIA devrait dévoiler leur carte graphique Volta de nouvelle génération qui éliminerait tous les problèmes de bande passante rencontrés avec les cartes graphiques de la génération actuelle en mettant en vedette des puces de 1 To/ s de mémoire empilés sur les DIE graphique. Plus d’informations que ici .
Auteur : K1ng0fNo0b Rédacteur Hardware pour monhardware.fr partenaire de War Legend
Source: monhardware.fr partenaire de War Legend
Vous pouvez vous tenir à jour en suivant notre partenaire sur #MHFR, ils répondent à votre besoin constant de rester à jour sur la technologie d’aujourd’hui. Suivez nous sur notre facebook ou notre twitter.
ces quoi ces news de folie mdrrrrrrrrr
Sympa ces news, elles sont vraiment bien travaillées.
J'adore
Thanks all ^^
ah ouai, comme d'hab chez nvidia, ils poussent fort et loin